Visualize X
This is transcription of the presentation I gave at VISUALIZEDio in November'14 in London. I talk about data, visualization and generative art.

Hi, My name is Marcin Ignac and my talk is called "Visualize X". Today I would like to talk about things that are possible to visualize.

I run a small studio called Variable. We specialize in data visualization and generative design.

A long time ago I've said:
"I don't do things that I can't see"
Back then I really meant that. I was focusing on visual style and aesthetics.

Also long time ago an Austrian-British philosopher Ludwig Wittgenstein said:
"The limits of my language are the limits of my world"*
My language is data visualization and code.

So if today you asked me
"What do you do"?
I would answer that I design
"Visual representations of the underlying systems."
Let me explain what I mean by that.
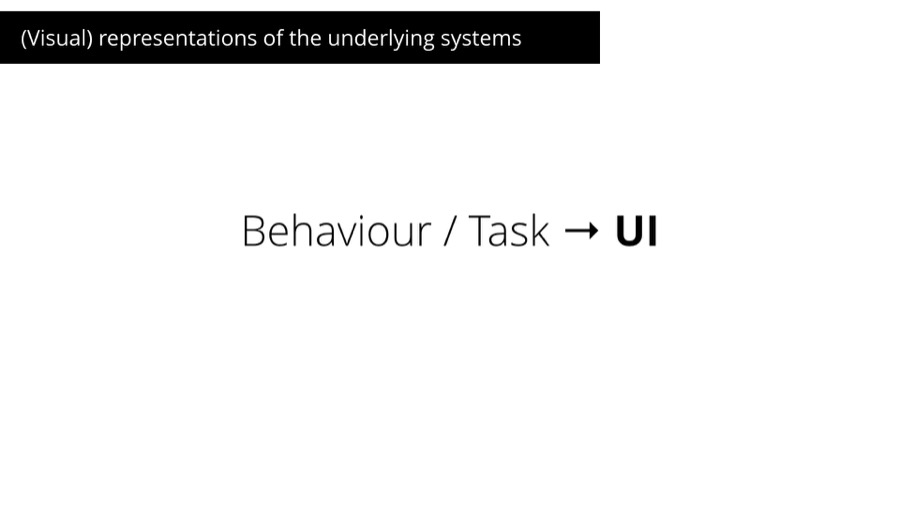
We can say that a visual representation of a behaviour or a task is the User Interface.
Take for example Pinterest. At first it seems like a website for browsing for inspiration.
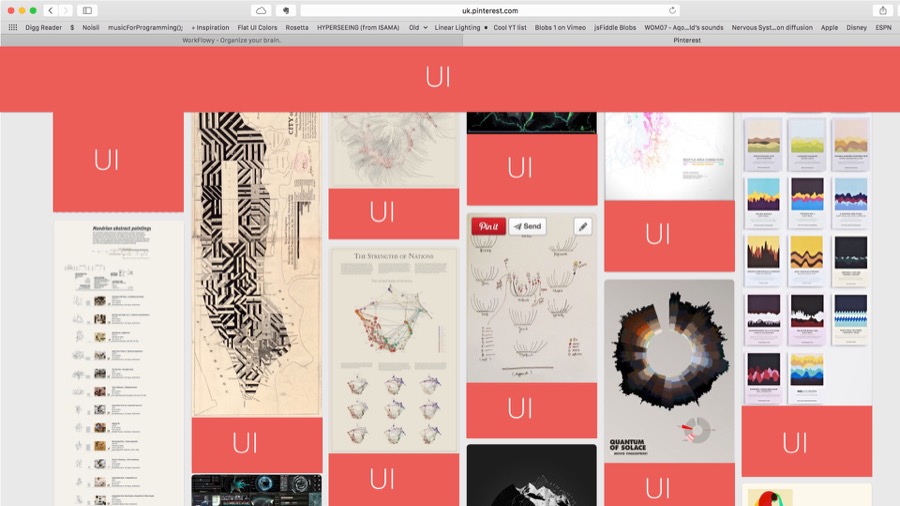
So why there is so much UI here? All these widgets, buttons, avatars, comments... I don't need that.
For me Pinterest is more like a website for repinning other peoples's pins.
So how a website focusing only on browsing image references could look like?
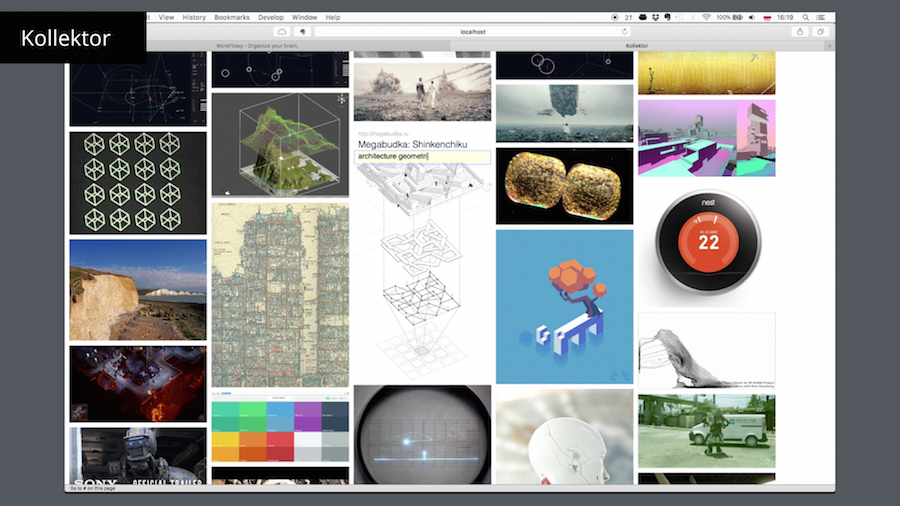
This is Kollektor, an image collecting website I've made. It's pretty much like Pinterest but there is almost no UI. To see a title you mouse over an image. To edit you click and hold, then enter the text inline.
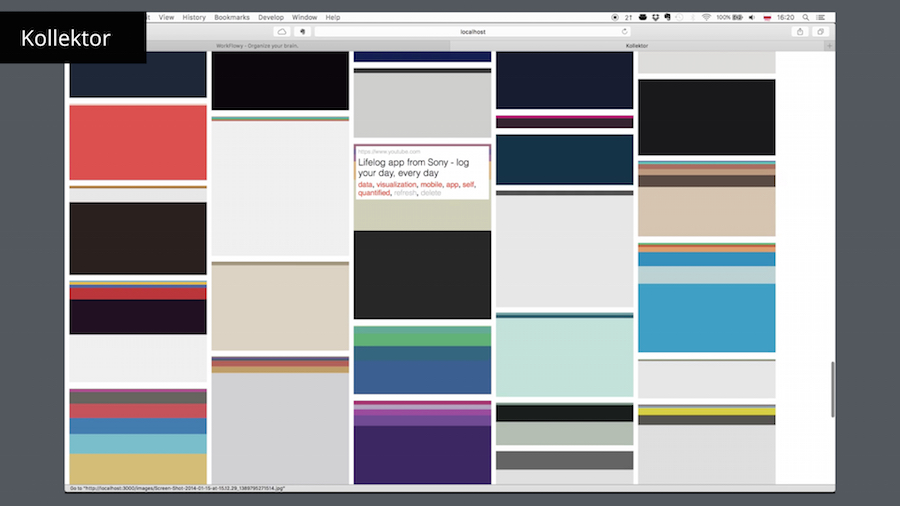
Now if we want to focus let's say on colors you can type /colors command and every image will be replaced by a palette of key colors and nothing else.

We can say that generative art is a visualization of an algorithm. We take a set of rules and convert them into a visual representation.
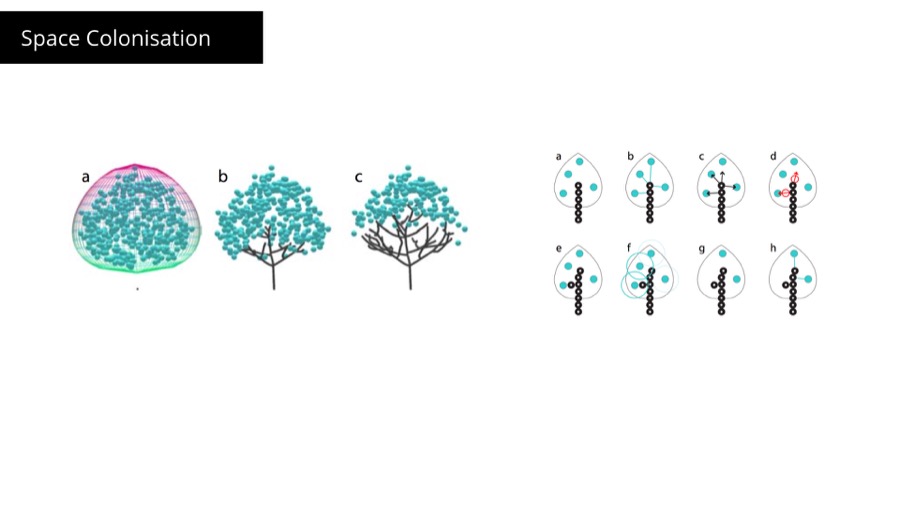
Space Colonization is an algorithm describing growth of plants. The way it works is that we populate available space with food particles called here hormones and we grow branches of the plan towards them.
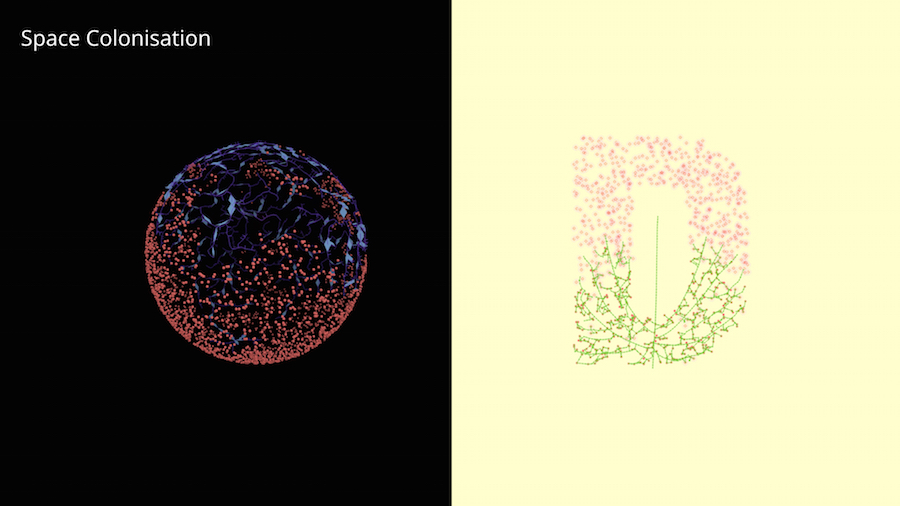
Here are two examples. On the left we have hormones spread on the surface of a sphere. On the right we are trying to grow a letter D.

And finally the reason why we all meet here today: visualization as a visual representation of data.
I have a little program called Tapper made by Dean McNamee. It's running constantly on my computer and tracks which applications are currently open.

I visualized this data in my project called Every day of my life. Each line represents one day, on the left side we have 00:00 and on the right 23:59. Each collor represents currently active application.

As you can see I don't sleep too much... and keep going to bed quite late. At the time in 2010-2012 I lived in Denmark. You can see a nice lunch break around 12:30am (in the middle) where I was going out to grab some food with friends. After moving to London that gap is gone and now I just work all the time :)

But let's move on to the main topic of this talk "Can you visualize X?"
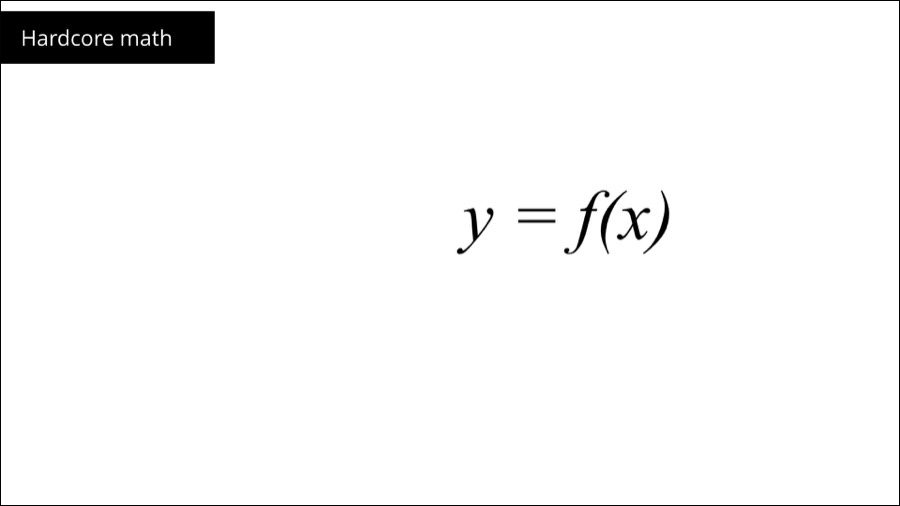
So what's X?
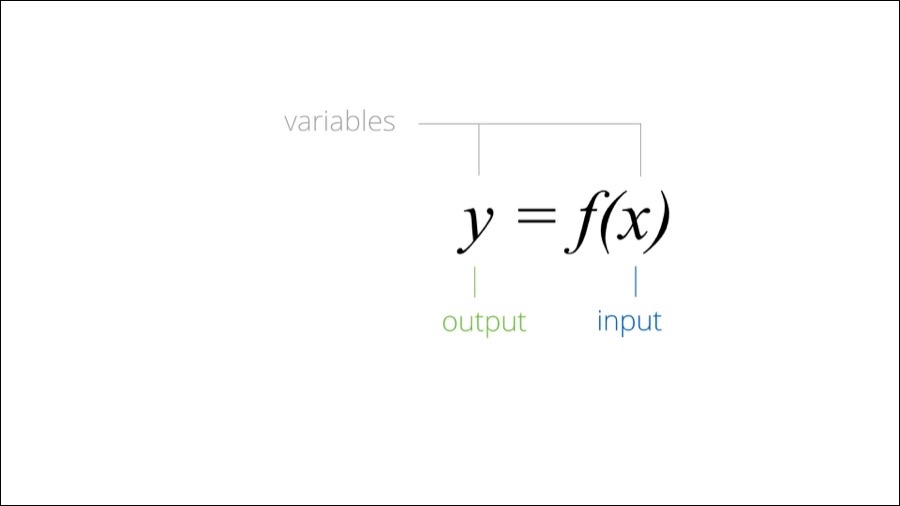
Let's have a look at how X is used in math. X and Y are called variables. We can say that Y depends on X and that Y is a result of function of X. We can call X an input and Y and output. If X changes then Y will usually change too.
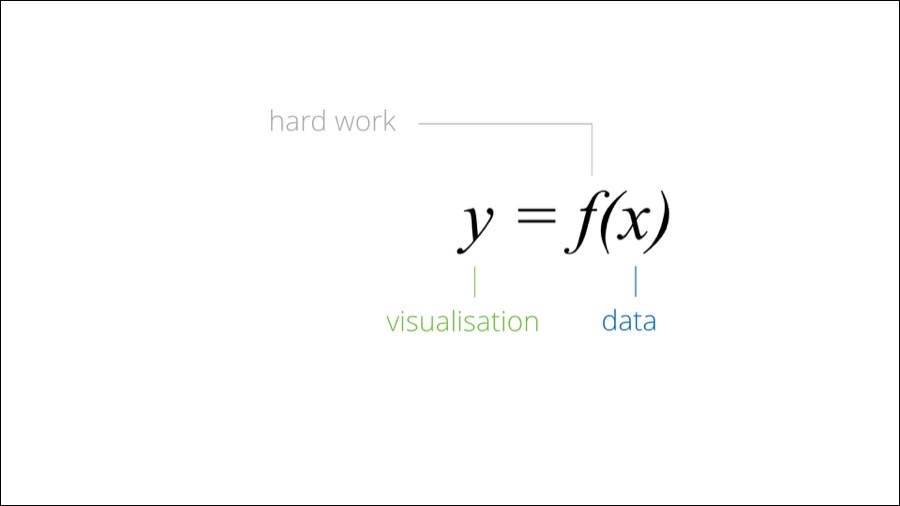
In the context of data visualization. X is data, Y is visualization and f() is hard work.

So when people come up to me and ask
Can you visualize X?
All I say is:
Yes, just give me the data, please.
We need the data in order to visualize it... And that's not always easy. There is several possible issues with that.

Issue No.1:
People think they know what they have but the reality is different.
Solution:
I take them on a Data Safari.

What is a Data Safari? It's a journey to the client's data land. We go and have a look at the data. What are the data spiecies? Arey they big or small? Are they simple or complex? Are they static or constantly changing? How much of the data is there?
We try to understand together what's available, how to access it and what's possible to do with that data.
Original photo by hrmann_2000
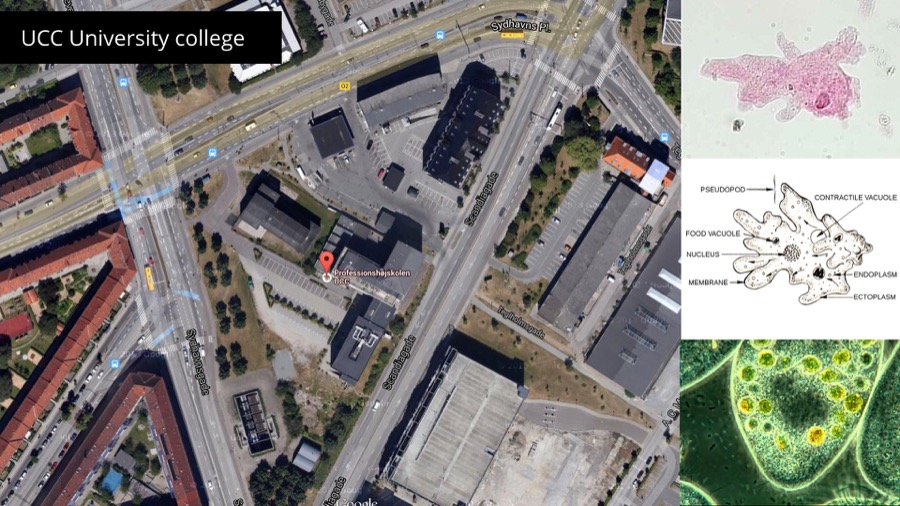
Let me give you an example. I'm currently working together with Kristoffer Ørum and Anders Bojen on a project for UCC University College in Denmark. We want to represent the school as a living organism.

We have access to a list of students groups, lessons schedule, classes etc.

We started by doing simple visualizations of all the student groups based on sample data. Each groups is a circle colored by major. Each circle contains of small points, one for each student. The older the student the brighter the point. The older the group the smaller it is.
Couple of interesting points here. It looks like there are majors and groups types with no groups at all. There are also groups with no students. So we dropped them. As it turned out later it was a bad idea. Once we started testing live data the schedule was updated and the missing data was available.
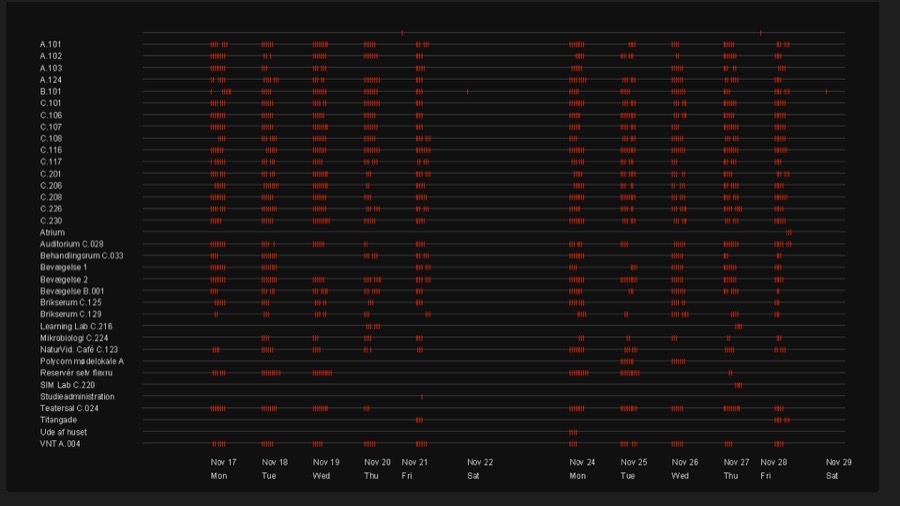
Then we looked at the schedule. It looks like everything is ok. Lessons start roughly each hour.
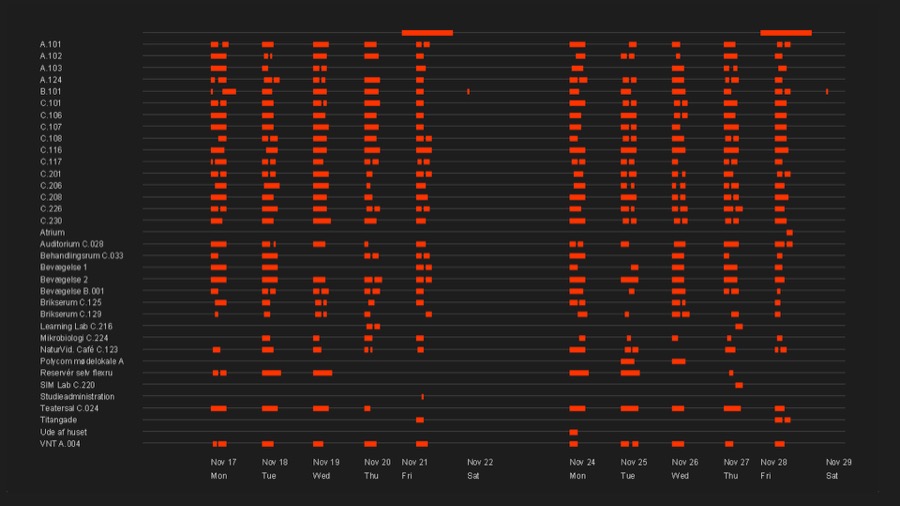
But then we plotted start and ending times we were getting and we discovered that lessons start and end back to back with no breaks between them. Another assumption that turned out to be not true. Once we discovered that we asked "Why?". Is it the database? Is it the scheduling software? Are we doing something wrong?
That's the purpose of Data Safari, go out there and start exploring, then start asking questions.

Isssue No.2
Ups, the data doesn't exist yet.
Solution a)
Can we create the data?
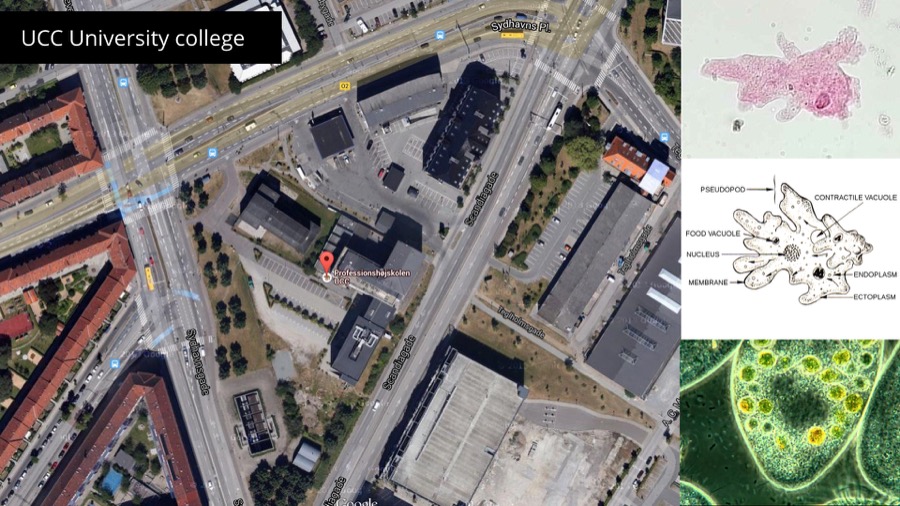
In the same project for UCC we want the student agents to move from classroom to classroom between lessons. The problem is that we don't have this type of information: how each classroom is connected via corridors to another. We have a map and the floor plan though.
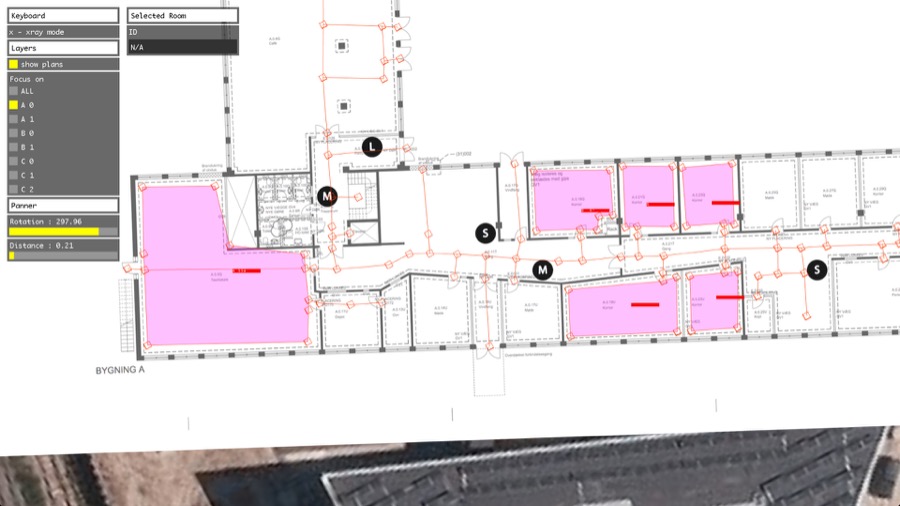
So I've built a tool that allows you to draw that information. Pretty much like in illustrator: you can draw points, connect them with lines, fill them to mark as room, etc.

It's a fully 3D map of interconnected floors across 3 buildings.
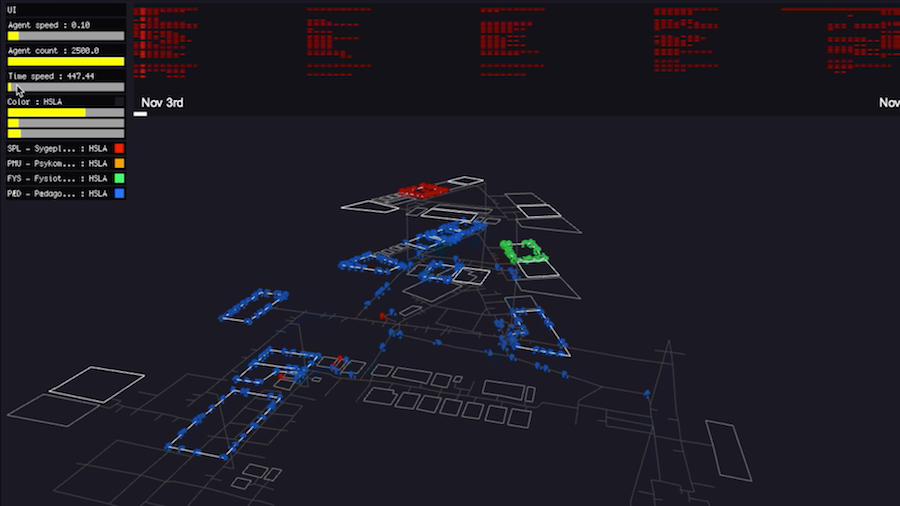
We use it for simulation student agents' movement. We also learn things. For example Physiotherapy students (green) have most of their classes in only one and the same classroom.
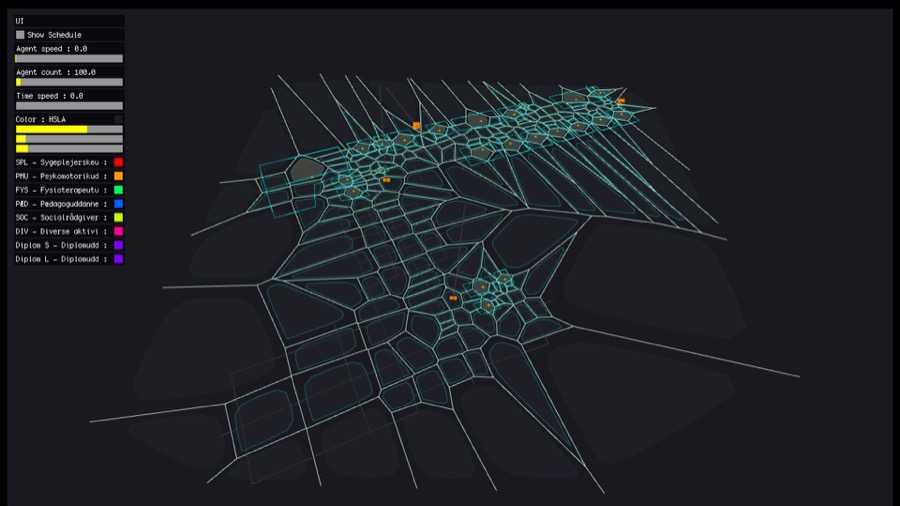
The next step for this project is to go beyond the schematic view and represent the school as a biological structure. Here we are experimenting with Voronoi cells.

Isssue No.2 continued
Ups, the data doesn't exist yet.
Solution b)
Can we use historic data? E.g. from the same period last year.

In summer of 2011 I collaborated with researchers from Danish Technical University on visualizing people activity during Roskilde festival - the biggest music festival in Denmark. We used mobile phones to scan for nearby bluetooth devices (other people's phones) to estimate number of people in the given area.
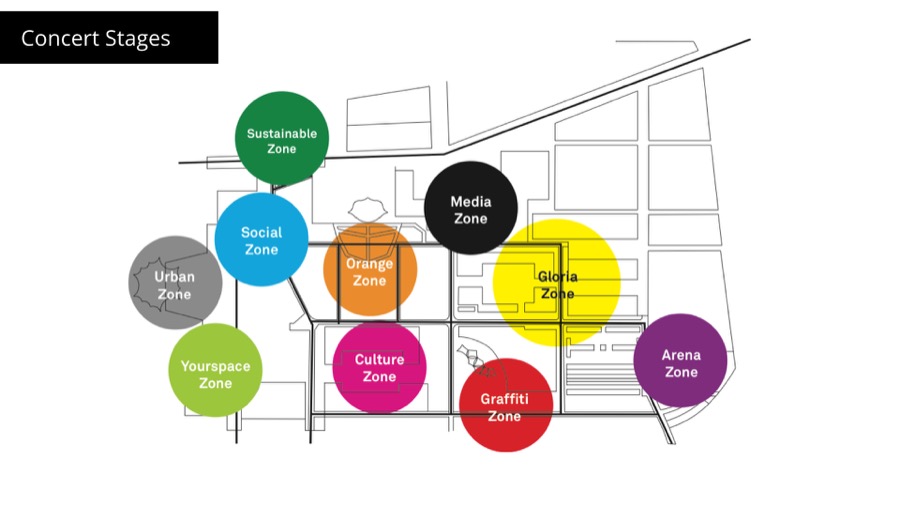
There was multiple stages and several blue tooth scanners for each one of them. The problem we had was trying to predict how the system will behave and what's the best way to visualize it.
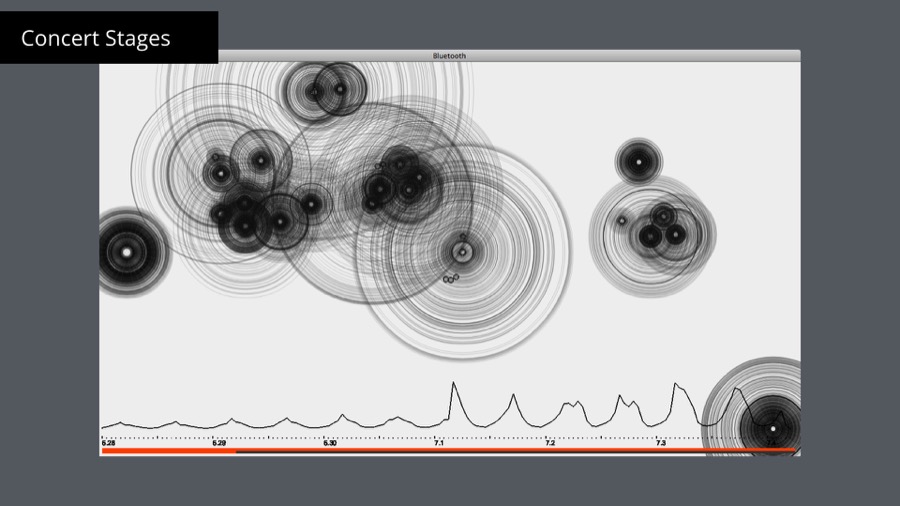
Luckily we had sample data from the previous year test. The circles represent the GPS positions of the bluetooth scanners and their size is the number of people they have detected.
On the bottom you see a graph of total of number people detected. You can clearly see daily rhythm there. The tracking started few days in advance with the construction work of the scenes and preparations. Then the days with bigger peaks show when the concerts actually happened.

The test visualizations above brought us to the final idea - visualizing data as a triangulated landscape where each vertex is a bluetooth scanner. The hight of the vertex is number of people nearby. Additionally they are grouped and colored by the name of the nearest stage. See Video

Isssue No.3
We have data but we can't show it to anybody.
Solution
I could have a solution if I knew the problem existed..
Last year I worked with a government organisation on visualizing their funding and how collaborations shape between sectors. It was an amazing project, based on linked data, deployed on the web, interactive. Unfortunately at the end of the project it turned out that the organisation is not yet ready to publish the data for various reasons. So the project is now in frozen state without any immediate data for release.

Here you can see one of several visualizations we developed. It's an organisation chart. It shows how many projects Imperial College London got funding for, what are other collaborators working on these projects and what kind of projects they do as well.
When working with data visualization that will be published on the web and with open data in particular. Make sure you know what are you doing. That the data is anonymized and you respect privacy.

Isssue No.3 continue
We have data but we can't show it to anybody.
Solution
There is another solution to that problem. You can always make it abstract (unreadable, unrecognizable) or use data driven generative art.
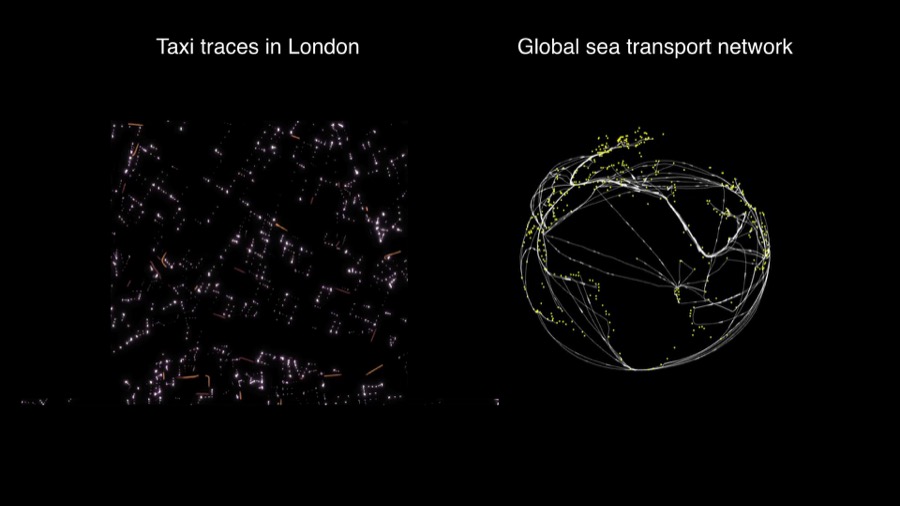
On the left we see trails of GPS positions taxis at night in London. On the right we see sea trafic visualization and how different ports are connected by shipping routes. Both of this visualizations look very similar...
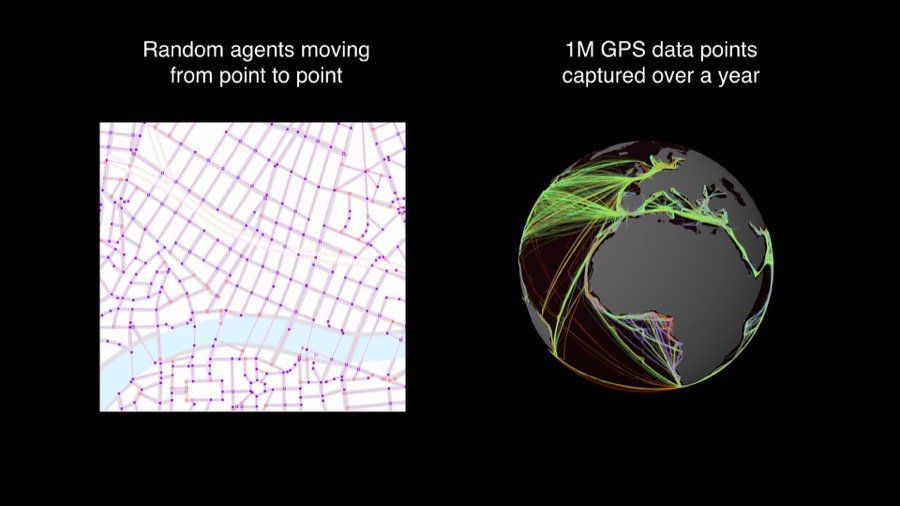
... beside the fact that the one on the left is fake. There is no real data behind it. It's just random agents following hand drawn city grid. The globe is visualized based on 1M GPS data points collected from vessel positions during whole year.
Simulations like the one with taxis are sometimes useful and only way to communicate the idea but the beauty of real world systems based on real data is incomparable.
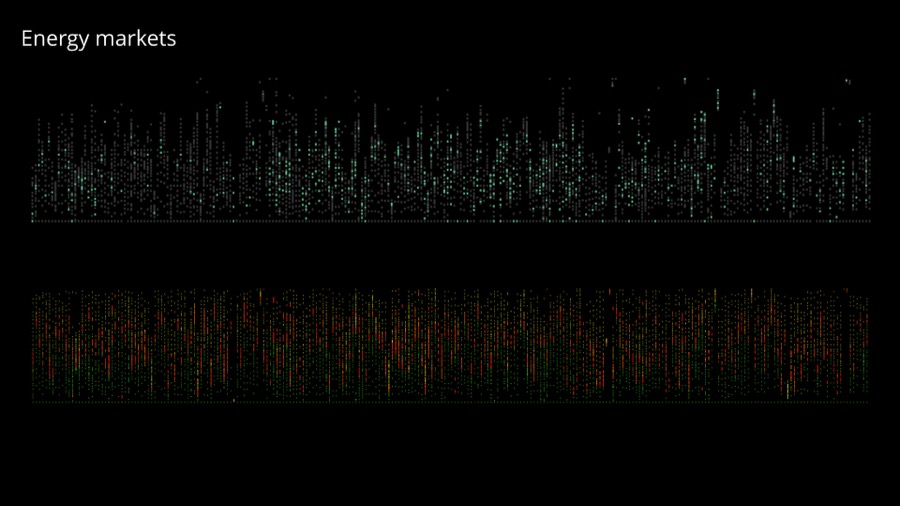
In 2013 I worked on visualizing fuel market prices in Singapore. We have the exact data about who bought for how much, when and how often. We can see how prices drift and what are the trends on the market. For obvious reasons the client didn't want to make it public. Actually it would be not that useful without a proper analysis anyway.
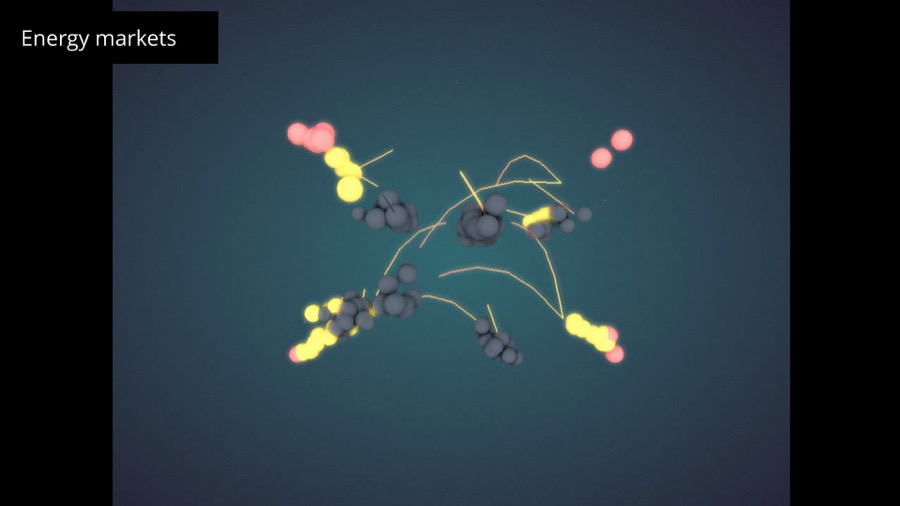
What I did instead is to visualize the rhythm of the market. You can see how transactions appear, who are the big players, how the whole systems gets quiet during weekend etc. I think this can sometimes be a much more powerful representation that raw data. For me data art is about communicating feelings.
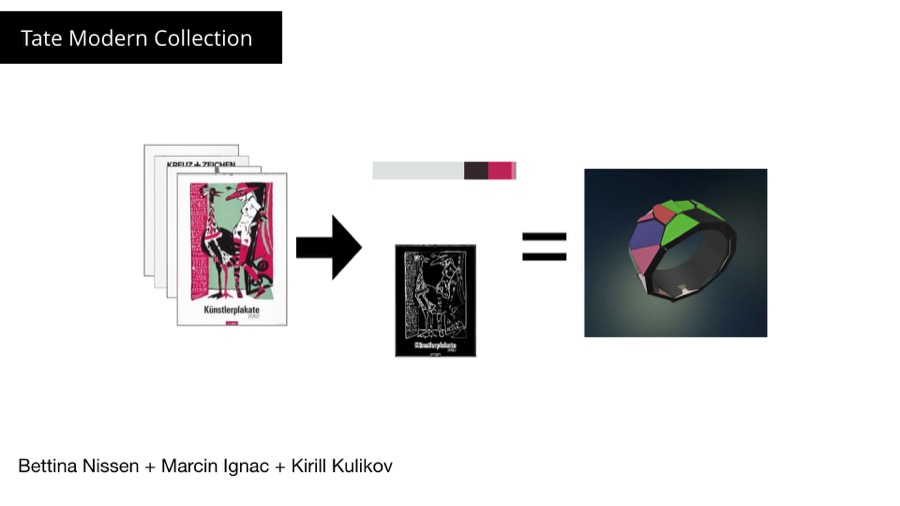
Earlier this year I took part in a 24h hackaton at Tate Modern. Together with Bettina and Kirl we came up with an idea of generating a physical artefact (a bracelet) from your visit to the gallery. Tate modern publishes the data for all their artworks but they don't include images the artwork themselves.

So we downloaded the whole internet :) Ok, a part of it. All 70'000 images references in the Tate's collection from their website. We then extracted color palettes from them using process similar to octree color quantization.

We also came up with a cleaver way to measure image complexity. Using OpenCV Kiril first used sobel filter to extract edges from the image and then counted the number of white pixels.

That gave us surprisingly good results. Simple (geometric) images have few edges and low score, more complex images have many edges.

We use the image complexity and color palettes to build a generative bracelet based on selected images. The idea was that the images would come from your favorites or for example from a chosen artist and the bracelet would be later 3D printed.

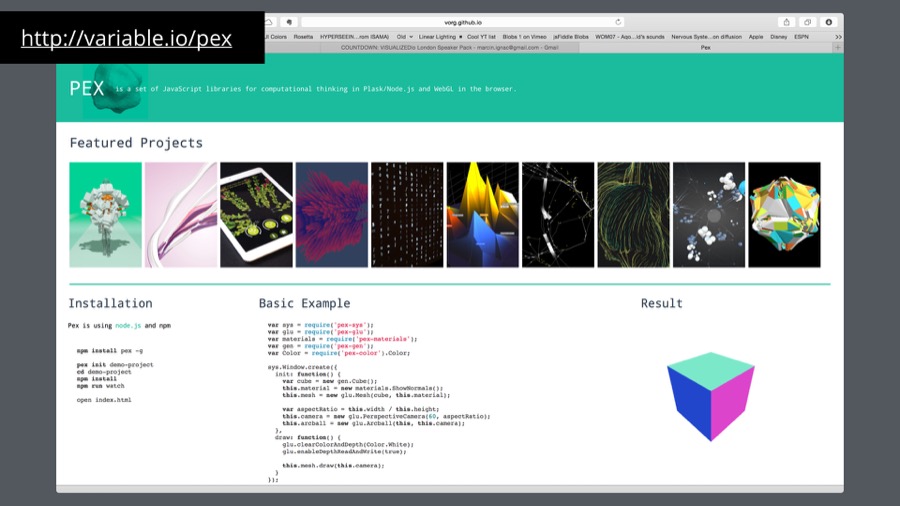
Pex is my own library I created to work with WebGL - 3D graphics in the browser.Today I'm very happy to finally open it to public. Go and check it out at http://vorg.github.io/pex/.
I call it a toolset for computational thinking as it's not targeting data visualizations only.
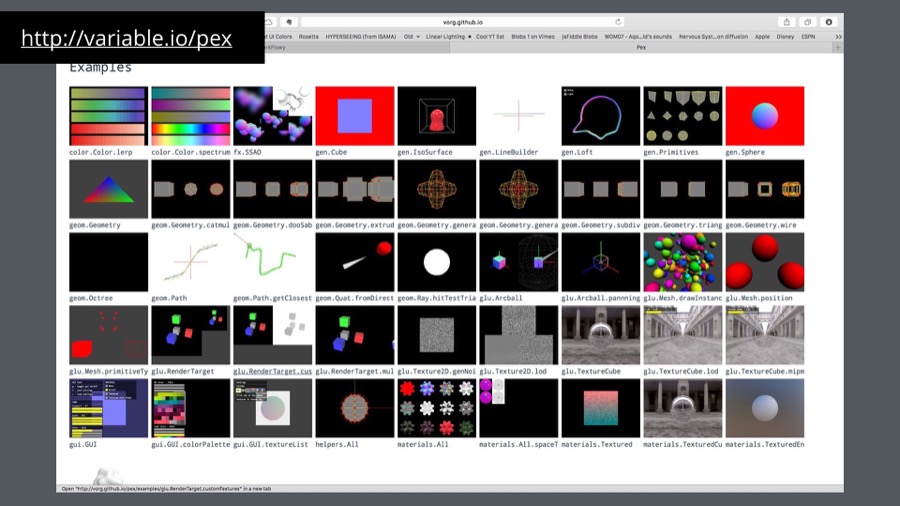
I use pex for 90% of my work nowadays and hope some of you will find it useful too. It's work in progress but you need to start somewhere.

Thank you!